深度学习作为人工智能领域的核心技术,其性能的优劣很大程度上取决于数据处理的质量与效率。数据是深度学习的“燃料”,而数据处理则是将原始“原油”提炼为高效能源的关键工序。本文将概述深度学习中常用的数据处理方法,并探讨其在计算机系统服务中的具体应用与价值。
一、深度学习中的核心数据处理方法
数据处理流程通常包括数据采集、清洗、标注、增强与标准化等环节,每个环节都对最终模型的性能有决定性影响。
- 数据采集与清洗:这是数据处理的第一步。目标是获取原始数据并消除其中的噪声、错误和不一致性。例如,在计算机系统服务的日志分析中,需要从海量、非结构化的系统日志中提取有效事件,剔除调试信息与重复条目。常用技术包括正则表达式匹配、异常值检测和数据去重。
- 数据标注:对于监督学习任务,高质量标注至关重要。在计算机系统服务的故障预测场景中,需要工程师根据历史日志对“正常”、“警告”、“故障”等状态进行精确标注,以训练分类模型。半监督和弱监督学习可以在标注数据不足时,利用大量未标注数据提升模型效果。
- 数据增强:旨在有限的数据基础上,通过变换生成新样本,以增加数据多样性和模型鲁棒性。在图像处理中常见(如旋转、裁剪),在计算机系统服务中,可以对时序数据(如CPU利用率、内存占用曲线)进行加噪、时间轴伸缩或片段重采样,模拟不同负载下的系统状态,使模型更能适应真实环境的波动。
- 数据标准化与归一化:不同特征(如CPU使用率、网络吞吐量)的量纲和范围差异巨大,直接输入模型会导致优化困难。通过Z-score标准化或Min-Max归一化,将特征缩放至相近的区间,可以加速模型收敛并提升性能。
- 特征工程与表示学习:传统方法依赖领域知识手动构建特征(如从请求日志中提取QPS、平均响应时间)。而深度学习的优势在于能够通过神经网络(如自动编码器、RNN)自动学习数据的深层特征表示,例如从复杂的系统调用序列中自动识别出潜在的攻击模式或性能瓶颈特征。
二、数据处理在计算机系统服务中的应用实践
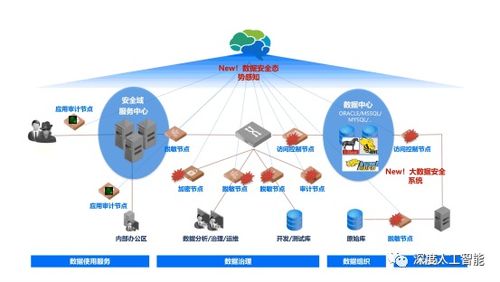
计算机系统服务(涵盖云计算、数据中心运维、分布式系统等)产生多源、海量、动态的监控数据,为深度学习提供了丰富的应用场景。
- 智能运维与故障预测:通过处理历史监控指标(CPU、内存、磁盘I/O、网络流量)和日志事件,构建时序预测模型(如LSTM、Transformer),可以提前预测硬件故障或服务性能退化,实现从“被动响应”到“主动预防”的转变。高效的数据清洗和特征提取是保证预测准确性的前提。
- 资源调度与优化:在云数据中心,通过对虚拟机历史负载数据、资源使用模式进行聚类分析和序列建模,可以更精准地预测未来资源需求,从而实现动态、自适应的资源调度与整合,提升资源利用率并降低能耗。这里的数据处理需要关注多维度指标的关联性与时序依赖性。
- 安全威胁检测:处理网络流量包、系统调用链和用户行为日志,利用深度学习模型(如卷积神经网络用于流量图像化分析,循环神经网络用于序列建模)可以异常检测模式,识别诸如DDoS攻击、内部渗透或恶意软件等安全威胁。实时数据流的快速处理和在线学习能力是关键。
- 服务质量保障与根因分析:当服务出现性能下降或故障时,需要快速定位根因。通过关联分析来自应用、服务器、网络和中间件等多层数据,并利用图神经网络等模型建模服务依赖关系,可以快速将异常指标(如延迟激增)追溯到具体的故障组件(如某个数据库节点或网络链路)。
三、挑战与未来展望
尽管数据处理方法不断进步,但在计算机系统服务领域仍面临挑战:数据隐私与安全(尤其在多租户环境)、处理高维异构数据的复杂性、对实时流式数据的高效处理需求,以及模型决策的可解释性要求。
随着自动化机器学习、联邦学习、持续学习等技术的发展,数据处理将更加智能化与自动化。结合领域知识图谱,构建系统状态的统一语义表示,也将进一步提升深度学习模型在复杂计算机系统服务中的理解与决策能力。
###
数据处理是深度学习应用于计算机系统服务的基石。从原始、混沌的系统数据中提炼出有价值的信息,不仅需要扎实的数据处理技术,还需要对计算机系统本身的深入理解。两者结合,方能驱动智能运维、资源管理、安全防护等服务的持续进化,构建更可靠、高效、自治的下一代计算基础设施。