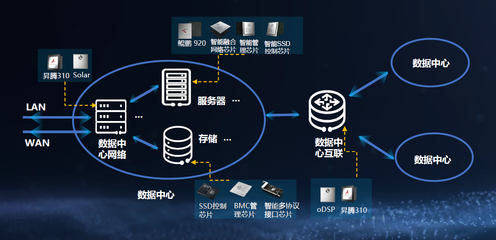
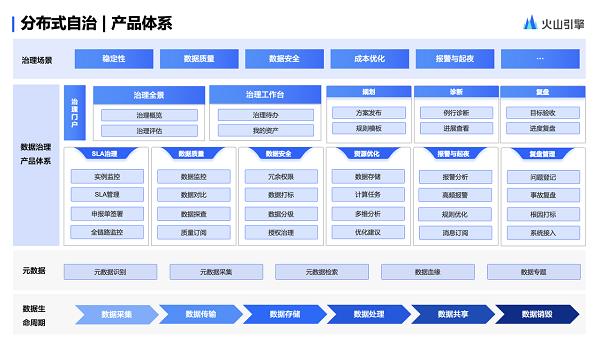
地质学作为一门以观察和描述为基础的学科,其发展早已离不开数据的支撑。上一部分我们探讨了地质数据的基本类型、采集方法与初步整理,本篇我们将深入地质数据处理的核心流程,重点阐述如何将原始的、杂乱的地质观测数据,转化为可靠、可用于地质解释与决策的有效信息。
一、 数据预处理:为分析奠定坚实基础
数据处理的第一步,也是至关重要的一步,是数据预处理。未经处理的原始数据往往包含错误、缺失值、异常值和不一致的格式,直接分析可能导致错误结论。
- 数据清洗:识别并处理数据中的错误。例如,校正因仪器故障或记录笔误产生的明显错误值;统一地层代号、岩石名称等专业术语的书写格式;处理GPS坐标中的格式不一致问题。
- 缺失值处理:地质数据常因采样条件限制或记录遗漏而存在缺失。处理方法需谨慎,可根据情况选择删除缺失记录、使用平均值/中位数填充,或采用更复杂的插值法(如基于空间关系的克里金插值)进行估算。
- 异常值甄别与处理:并非所有异常值都是错误,它可能指示特殊地质现象(如矿化异常)。需要通过统计方法(如箱线图、Z-score)结合地质知识进行判断。对于确认为误差的异常值,可予以修正或剔除;对于有地质意义的异常值,则应保留并重点分析。
- 数据变换与标准化:当数据量纲或数量级差异巨大时(如将岩石密度(g/cm³)与地球化学元素含量(ppm)一同分析),需进行标准化(如Z-score标准化)或归一化处理,以消除量纲影响,使不同特征具有可比性。
二、 数据分析与解释:挖掘数据内涵
预处理后的数据便进入了核心分析阶段,目的是揭示数据中隐藏的模式、关系和规律。
- 统计分析:这是最基础的分析方法。包括:
- 描述性统计:计算均值、方差、标准差、频率分布等,了解数据的基本特征。例如,统计某地区一批岩石样本的SiO2含量范围与集中趋势。
- 推断性统计:通过假设检验(如t检验、方差分析)比较不同地质单元(如两个岩体)的某项指标是否存在显著差异;通过相关性分析(如皮尔逊相关系数)探讨不同变量(如Cu含量与磁化率)之间的关联程度。
- 空间数据分析:地质现象具有强烈的空间属性。此分析关注数据随地理位置的变化规律。
- 空间插值:根据离散采样点的数据(如钻孔品位),预测未采样区域的值,生成连续的表面图。常用方法有反距离权重法(IDW)和克里金法(Kriging),后者能更好地反映地质变量的空间结构。
- 趋势面分析:将观测值分解为区域趋势、局部异常和随机噪声,用于识别大范围的构造背景和局部矿化异常。
- 多元数据分析:当地质问题涉及多个相互关联的变量时(如一套地球化学数据包含数十种元素含量),需采用多元分析方法。
- 主成分分析(PCA):将多个相关变量转化为少数几个不相关的主成分,用于降维和识别控制数据变异的主要因素(如矿化作用、围岩蚀变)。
- 聚类分析:根据数据的相似性,将样本或变量自动分组,可用于岩石分类、划分地球化学省等。
三、 数据可视化与成果表达
“一图胜千言”,清晰的可视化是理解复杂地质数据和传达研究成果的关键。
- 基础图件:包括经过数据点标注的地质图、各种直方图、散点图、箱线图等,直观展示数据分布与关系。
- 专业图件:
- 等值线图与三维表面图:基于空间插值结果,展示物探异常、地层厚度、品位变化等的空间展布。
- 剖面图与栅状图:综合钻孔、测井等多源数据,展示地下地质体的三维形态与相互关系。
- 多元统计图:如PCA得分图、载荷图,聚类分析的树状图等,直观呈现多元分析结果。
- 综合图件与报告:将处理分析后的数据、图件与地质解释相结合,编制综合性的成果图(如成矿预测图)和文字报告,是数据处理的最终产出,直接服务于矿产勘查、工程地质、环境评价等实际工作。
迭代与集成的数据处理思维
现代地质数据处理并非一个单向的线性流程,而是一个“数据获取 → 预处理 → 分析解释 → 可视化 → 新问题/新数据”的迭代循环。每一次分析都可能揭示新的问题,从而需要补充数据或调整处理方法。随着信息技术的发展,地理信息系统(GIS)、三维地质建模软件和专业统计分析工具(如R、Python)已成为地质数据处理不可或缺的平台,实现了多源、海量地质数据的高效集成、管理与深度挖掘。掌握从基础理论到软件工具的全链条数据处理能力,是将地质学家从繁重的数据整理中解放出来、更专注于地质科学本质创新的关键。